Seams of strategic gold are buried in raw legal data, and Karl Harris, chief executive officer of the legal analytics company Lex Machina, wants litigators to know his company has the best technology to dig them out.
Lex Machina’s proprietary Legal Analytics platform mines and processes data to deliver insights about judges, lawyers, parties, and the subjects of the cases themselves, culled from millions of pages of litigation information.


Harris’ background is well-suited to his position. He holds a J.D. from Stanford Law School, an M.S. in Computer Sciences from the University of Texas at Austin, and an A.B. in Computer Science from Dartmouth College. Before he became CEO, he served as chief technology officer and vice president of products for Lex Machina, which is owned by LexisNexis. Before that, he was a fellow at XSeed Capital Management, a seed stage venture firm and Lex Machina’s lead investor.
Above the Law caught up with Harris to find out about his firm’s process, and why he thinks it’s superior to the “quick and dirty” data crunching of other companies in the field.
This interview has been edited for length and clarity.
 ATL: How did you come to the business of legal data analytics?
ATL: How did you come to the business of legal data analytics?
KH: Three pieces of my background led me here. First, I attended Stanford Law School, and I’m an active member of the California bar, so I’m obviously familiar with the legal space. Second is my products and technology background. Before law school, I was a software engineer. I built a mobile analytics product that at one point was used on 90 percent of the iPhones worldwide. So, I came with a lot of experience in analytics prior to joining Lex Machina.
Third is entrepreneurship. The mobile analytics company I mentioned was Flurry, a startup that was ultimately acquired [by Yahoo]. Lex Machina was a venture-backed startup before it was acquired by LexisNexis. Those three things were how it all came full circle for me.
Tell us about legal analytics. What are some features specific to the legal field?
Legal analytics is similar to other spaces in that it’s all about data-driven decision making. What’s unique about the law is the underlying data — the briefs, memos, and filings that go into litigation — are all largely unstructured, just text filed with the court. Legal analytics is all about using smart technology, such as natural language processing and machine learning that allows you to make sense of these massive amounts of text.
In what areas of the law are data analytics most useful?
The uses fit into two broad categories.
One is making sure you land more clients as a law firm, or helping you select the right law firm as in-house counsel. What is the litigation track record of your opposition? How did a specific attorney perform before this judge?
The second is winning cases. How is opposing counsel likely to behave? How is the judge likely to behave? What’s the best thing we should do in our case based on what has worked and what hasn’t worked with all the people involved?
Do you analyze judges, venues, and juries?
Yes, we analyze venues. Certainly courts, and administrative bodies like the U.S. Patent Trial and Appeal Board and the U.S. International Trade Commission. We analyze jury trials and jury verdicts so we can see what’s happened in cases that have had different jury outcomes in different venues.
We’re also able to analyze the behavior of judges at all stages of litigation. Only a small fraction of cases actually end up with a jury. The majority are either settled, there’s a procedural outcome, or a judge-driven outcome. In the majority of cases, the judge’s behavior is the most important. That’s where analytics is really a huge factor, looking at a judge’s track record over time, in certain situations similar to yours.
You have a legal background and many of your team members have legal backgrounds. Why do you think that’s important?
Let me describe the team that builds the product. We have the engineering team focused on technology and then we have the data-team members, who all have legal backgrounds. We have folks on the team who were in-house counsel for decades prior to joining Lex Machina. And there are two reasons that’s important.
Number one is, we want to make sure we’re solving the problems that real lawyers actually want to solve. We can do that by talking to customers, but an additional way is to have people who’ve actually been lawyers making decisions about what would have helped them in their practice. We want to make sure we’re doing the right things when writing code and algorithms to interpret legal data. By having legal expertise fused into the engineering team, it helps us make sure we’re doing a good job from the ground up rather than finding problems later.
You have decried the use of “quick and dirty” analytics. What do you mean by that, and why do you think it is such a problem?
The only way for people to have faith in using data to make decisions is if that data is correct, right? You may have heard the phrase, “garbage in, garbage out.” If you can’t trust the data you’re using to make decisions, you’re going to make garbage decisions. We’re mining a lot of unstructured data that was never intended for this use, and we take real pride and great care to make sure that you can trust the data.
For example, with Lex Machina, you can always drill down to the individual docket to see why a finding is relevant, or where money changed hands. We call that showing our work. If you want to know why a breach of contract was found in a particular case, you can drill right down to the legal document. That is very hard to do and has taken years of investment in our platform.
We also correct for mistakes in legal records. The docket is literally just typed in by a clerk, who might misspell the names of people or law firms or list someone as being on the plaintiff’s side who’s on the defense side. And if you just regurgitate what the court record says, you’re potentially feeding inaccurate information to users of your product. At Lex Machina, we correct all that information so you can trust what you see.
You have to show comprehensive case resolutions as well. Who won? Did money change hands in the case? Was there a remedy like a permanent injunction? A lot of the quick and dirty providers of legal analytics don’t do that. They basically resell the dockets you could get from the court. We don’t think that’s analytics. We certainly don’t think you should trust that information. You shouldn’t use it to make strategic decisions in your cases.
In your product, how do artificial intelligence and natural language processing intersect with human review?
Well, we like to say the machine gets us 90 to 95 percent of the way there and humans do the rest. So, the machine narrows down the cases that an actual person has to review. Then we call in our legal data team and they go in and verify that, for example, a dollar amount is correct. Or the finding is correct. Those important inflection points are reviewed to make sure they’re right.
Was it a challenge to develop your natural language processing software?
At Lex Machina, our core intellectual property is our natural language processing technology as applied to the law. We didn’t want to reinvent the wheel, but we realized that most readily available natural language processing couldn’t process the rules of litigation, the Rules of Civil Procedure, the process of a case. We found that off-the-shelf technology just wasn’t good enough, so we tailored our system to have legal knowledge, so it can make decisions based on what has to happen according to the rules of law.
And we are uniquely positioned because we have hundreds of millions of data points that we can use to train custom machine-learning algorithms that require huge data sets. When we started Lex Machina, there was no input set for the law. We spent 10 years building this massive data set, and now we’re actually able to feed that into machine-learning algorithms. We can do more at scale than we’ve ever been able to do. It’s the next frontier. We finally have enough analytics to apply machine learning to the law in a way that no one else can do.
We also constantly update cases. If you look at analytics solutions from other companies, so many times you’ll see that the case hasn’t been refreshed in over a year. We invest the time, money and resources to make sure that all of our cases are refreshed on a daily basis. This is resource intensive, but it’s the only way to have data that can be trusted.
Earlier, you mentioned that Lex Machina shows its work. What does that entail? What do you show your clients?
In the product itself, you can always dive down to a document that shows where a particular situation occurred. Let me show you an example that I’ll use to illustrate the necessity of human review.
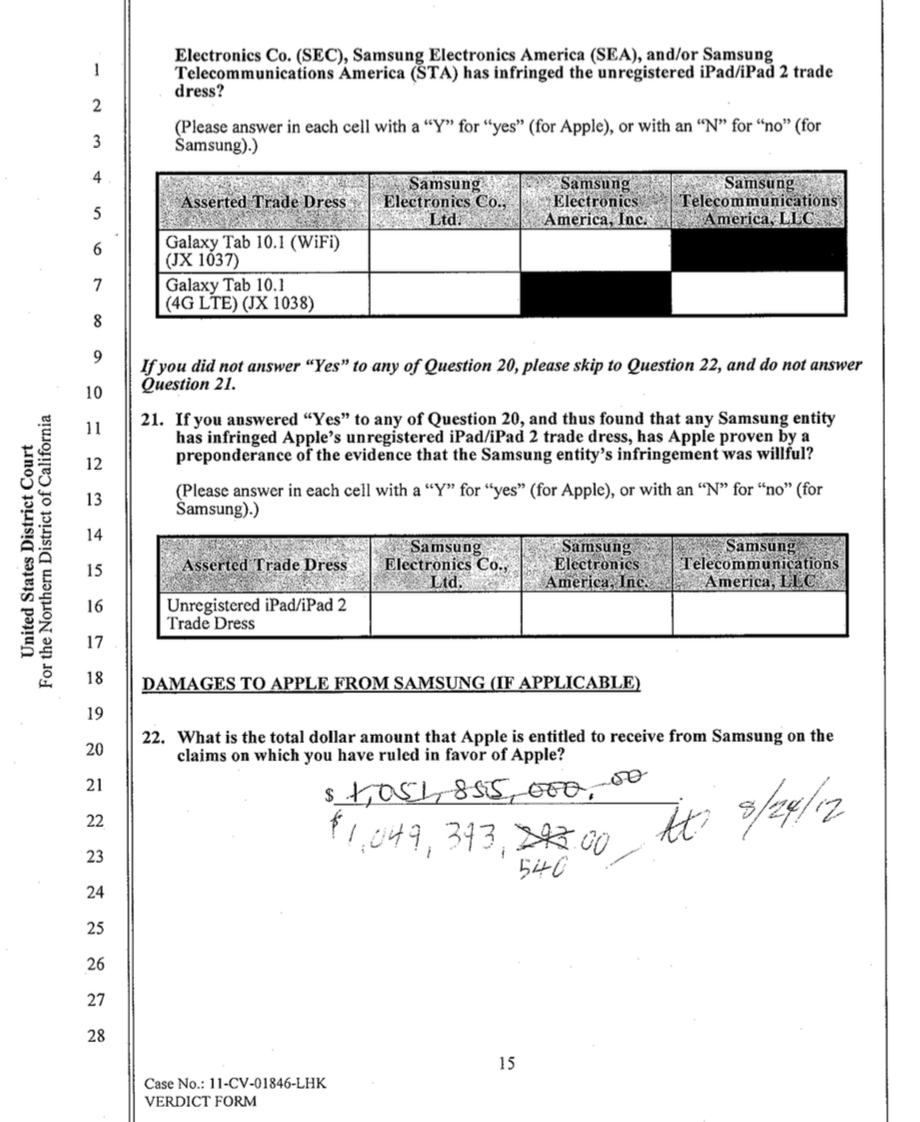
This is the jury verdict in the Apple versus Samsung case from several years ago, which you may remember was a huge patent litigation case. That is the billion dollar award.
As you can see it was hand-written, then crossed out and written again here, and initialed. No current optical character recognition technology can make sense of this number with confidence.
So when I say technology-assisted human review, I mean our system can say: “In this document, on this page on this line, there’s a big jury verdict. A human needs to go in and read it and make sure it’s correct.”
Some state courts jurisdictions might not have electronic filing yet. Does this cause problems for you?
Yes, state courts are a challenge. They continue to be fragmented, but they’re coming online at a very rapid pace. We target large metro areas, and by and large those places are going to have electronic filing systems.
Also, state courts are finally realizing that the data they have is valuable. Records should be online for folks to access for purposes of openness and transparency in the law, but if companies like LexisNexis and Lex Machina will pay the court to buy that data so that we can use it for analytics, and they see it as a possible revenue stream, that’s an incentive to move quickly.
Dig Deeper
Lex Machina’s unique Legal Analytics Platform combines the latest advances in computer science with in-house legal expertise and hundreds of millions of data points to deliver clean, in-depth analytics developed with the needs of practitioners in mind. The platform enables litigators to craft successful strategies, win cases, and close business. For more information, visit the Lex Machina website.